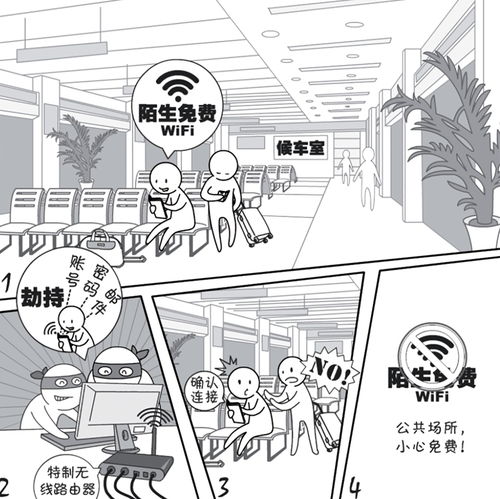
在數字化浪潮中,B端產品官網已成為企業展示實力、吸引客戶的重要門戶。尤其對于動漫產品這類富有創意和情感內涵的行業,如何通過體驗設計思維優化官網,并利用信息網絡實現高效經營,是提升市場競爭力的關鍵。以下從設計策略、信息架構和網絡經營三個方面展開論述。
體驗設計思維應以用戶為中心,聚焦B端客戶的需求。B端客戶通常是企業采購者或合作伙伴,他們關注產品的專業性、合作效率及長期價值。在設計官網時,需強調清晰的信息層級和直觀的導航。例如,首頁應突出產品特色、案例展示和合作優勢,使用視覺元素如動態動漫演示或交互式圖表來增強吸引力。同時,通過用戶調研和數據分析,優化頁面布局,確保關鍵信息(如產品規格、定價方案、技術支持)在3秒內可被獲取,提升用戶體驗的流暢性和滿意度。
信息架構是官網設計的核心,需結合動漫產品的特性進行組織。動漫產品往往涉及多樣化的內容,如IP授權、動畫制作、衍生品開發等。官網應采用模塊化設計,將信息分類為產品介紹、成功案例、行業解決方案、資源下載等板塊。利用信息網絡思維,建立內部鏈接和標簽系統,便于用戶快速跳轉和深度探索。例如,在案例頁面中,嵌入相關產品的技術文檔或視頻教程,形成知識網絡,幫助客戶全面了解產品價值。響應式設計確保在不同設備(如PC、平板)上的無縫訪問,并使用微交互(如懸停效果、加載動畫)來增強情感連接,這與動漫產品的創意本質相契合。
信息網絡經營是推動官網轉化為商業價值的關鍵。通過整合社交媒體、SEO優化和數據分析工具,構建一個動態的網絡生態。例如,在官網上設置博客或新聞板塊,定期發布行業洞察、產品更新和客戶故事,利用SEO策略提升在搜索引擎中的排名,吸引潛在客戶。同時,嵌入CRM系統或在線咨詢工具,實時收集用戶行為數據,分析訪問路徑和轉化率,從而優化內容策略。對于動漫產品,還可以利用信息網絡開展合作伙伴計劃,例如通過官網招募IP授權商,建立社區論壇促進用戶互動,形成口碑傳播。這不僅能提升品牌影響力,還能加速銷售轉化和長期合作。
B端產品官網的設計應深度融合體驗設計思維,以用戶需求為導向,優化信息架構,并借助信息網絡實現高效經營。對于動漫產品而言,這種整合不僅提升了專業形象,還強化了情感共鳴,最終驅動業務增長。企業需持續迭代,結合市場反饋和技術趨勢,打造一個既直觀又互聯的數字門戶。